Git笔记
1 Git配置
1.1 配置级别及配置项
git配置级别主要有以下3类:
仓库级别 local 【优先级最高】 当前仓库下的.git/config文件中
用户级别 global【优先级次之】 windows当前用户目录的 .gitconfig 文件中
系统级别 system【优先级最低】 Git安装目录下的 etc/gitconfig 文件中
查看配置项
1 | |
编辑配置项
1 | |
基础配置
1 | |
1.2 配置SSH公钥
1 | |
2 Git核心
Git理论基础工作区域Git本地有三个工作区域:工作目录(Working Directory)、暂存区(Stage/Index)、资源库(Repository或Git Directory)。如果在加上远程的git仓库(Remote Directory)就可以分为四个工作区域。文件在这四个区域之间的转换关系如下:
- Workspace:工作区,就是你平时存放项目代码的地方;
- Index / Stage:暂存区,用于临时存放你的改动,保存即将提交到文件列表信息;
- Repository:仓库区(或本地仓库),就是安全存放数据的位置,这里面有你提交到所有版本的数据。其中HEAD指向最新放入仓库的版本;
- Remote:远程仓库,托管代码的服务器,可以简单的认为是你项目组中的一台电脑用于远程数据交换。
Git的工作流程:
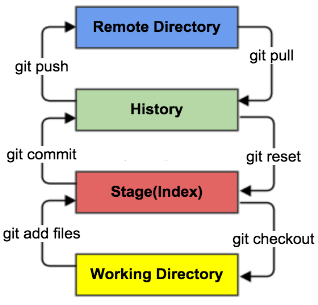
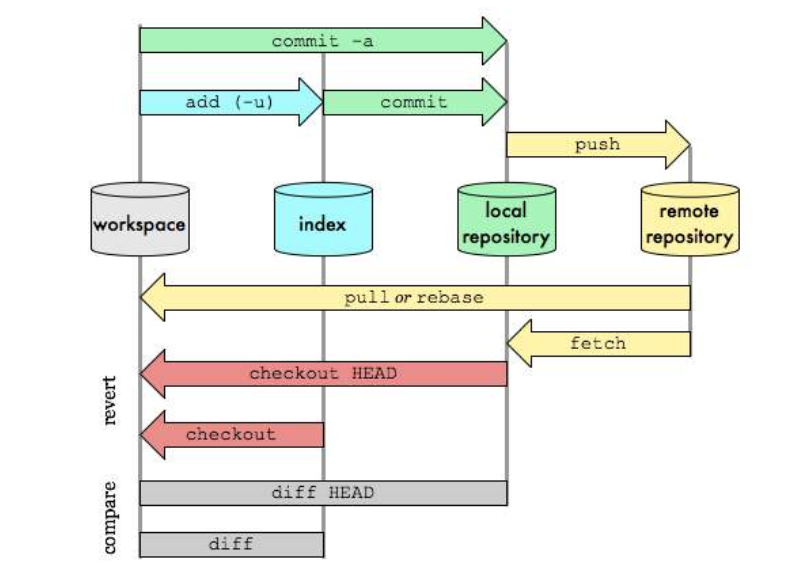
核心命令
1 | |
注意:
git diff 比较的是文件的内容,而非是否增加或减少了新的文件
1
2
3
4
5git diff # 不加任何参数,将工作区(未add的内容)和暂存区进行比较;
git diff HEAD # 将工作区与HEAD指针指向的commit进行比较,一般来说我们当前的改动就是在HEAD指向的commit的基础上进行改动;
git diff --cached # 将暂存区与当前commit进行比较;
git diff dev # 将工作区与目标分支的最新commit进行比较;
git diff [commitId_1] [commitId_2] # 将两个commit进行比较。git status 只显示文件的状态,不指明具体的变更内容
3 .gitignore
在**.gitignore**文件中设置相应的忽略规则,据此实现忽略指定文件的提交。
1 | |
4 连接远程仓库
远程仓库必须事先建立~ 注意,近年新创建的仓库,主分支全部==从master变成了main==。不过本地分支和远程分支的名字本来就不需要相同,所以建立恰当的追踪关系即可。
方法一:推荐
- 先在远程创建一个仓库,clone下来
- 把clone下来的文件复制到本地已有的项目里面
- 在Idea中,本地项目自动完成和远程仓库的关联
- (因为clone下来的.git文件中记录了远程仓库的信息)
此方法对Github和Gitee同样有效
1 | |
方法二:
在已有的项目中执行 git init 初始化git仓库
执行下面的命令关联远程已经存在的仓库
1
2
3
4
5# 等同于方法一中将.git文件复制到现有的项目中来
git remote add origin https://gitee.com/qizidog/GitTest.git
# 如果clone的远程库已经设置过关联仓库了,需要通过其他命令修改关联仓库,具体方式通过帮助查看
git remote --help
5 本地分支和远程分支
5.1 branch操作
1 | |
5.2 fetch操作
1 | |
5.3 pull操作
1 | |
pull操作相当于fetch操作和merge操作的结合,以下两种写法等效:
1 | |
出现错误
1 | |
5.4 push操作
推送==指定的本地分支==到==指定的远程分支==
1
2# 将本地某个分支推送到远程的指定分支
git push <远程主机名> <本地分支名>:<远程分支名>如果==省略远程分支名==,则表示将本地分支推送至与之存在”追踪关系”的远程分支(通常两者同名),如果该远程分支==不存在则会被新建==。
1
git push origin master上面命令表示,将本地的master分支推送到origin主机的master分支。如果后者不存在,则会被新建。
如果==省略本地分支名==,则表示删除指定的远程分支,因为这等同于推送一个空的本地分支到远程分支。
1
2
3
4# 慎用!删除远程仓库的分支(注意空格)
git push origin :master
# 等同于
git push origin --delete master上面命令表示删除origin主机的master分支。
如果==当前分支==与远程分支之间==存在追踪关系==,则本地分支和远程分支都可以省略。
1
git push origin上面命令表示,将当前分支推送到origin主机的对应分支。
如果==当前分支只有一个追踪分支==,那么主机名都可以省略。
1
git push如果当前分支==与多个远程主机存在追踪关系==,则可以使用==-u==选项指定一个==默认主机==,这样以后就可以不加任何参数使用git push。
1
git push -u origin master上面命令将本地的master分支推送到origin主机,同时指定origin为默认主机,后面就可以不加任何参数使用git push了。后面遇到过一点问题,本地分支和远程分支的名字不一样时,直接
git push会失败,最好还是保持本地分支和远程分支名字一致。
5.5 关联远程仓库
一般来说,先建立本地仓库和远程仓库的联系,再建立本地分支和远程分支之间的追踪关系。
绑定远程仓库相关信息的命令均在git remote下,具体使用方式可通过git remote -h查看帮助文档。
1 | |
5.6 建立追踪关系
建立追踪关系后可以简化push指令,也可以在git status时查看本地和远程进度的比较
建立追踪关系的三种方式:
手动建立追踪关系
1
git branch --set-upstream-to=<远程主机名>/<远程分支名> <本地分支名>push时建立追踪关系
1
git push -u <远程主机名> <本地分支名>新建分支时建立跟踪关系
1
git checkout -b <本地分支名> <远程主机名>/<远程分支名>
查看追踪关系:
1 | |
取消追踪关系
1 | |
5.7 stash操作
应用场景:
- 当正在dev分支上开发某个项目,这时项目中出现一个bug,需要紧急修复,但是正在开发的内容只是完成一半,还不想提交,这时可以用git stash命令将修改的内容保存至堆栈区,然后顺利切换到hotfix分支进行bug修复,修复完成后,再次切回到dev分支,从堆栈中恢复刚刚保存的内容。
- 由于疏忽,本应该在dev分支开发的内容,却在master上进行了开发,需要重新切回到dev分支上进行开发,可以用git stash将内容保存至堆栈中,切回到dev分支后,再次恢复内容即可。
总的来说,git stash命令的作用就是将目前还不想提交的但是已经修改的内容进行保存至堆栈中,后续可以在某个分支上恢复出堆栈中的内容。这也就是说,stash中的内容不仅仅可以恢复到原先开发的分支,也可以恢复到其他任意指定的分支上。git stash作用的范围包括工作区和暂存区中的内容,也就是说没有提交的内容都会保存至堆栈中。
(1)git stash save “save message” : 执行存储时,添加备注,方便查找,只有git stash 也要可以的,但查找时不方便识别。
(2)git stash list :查看stash了哪些存储
(3)git stash show :显示做了哪些改动,默认show第一个存储,如果要显示其他存贮,后面加stash@{$num},比如第二个 git stash show stash@{1}
(4)git stash show -p : 显示第一个存储的改动,如果想显示其他存存储,命令:git stash show stash@{$num} -p ,比如第二个:git stash show stash@{1} -p
(5)git stash apply :应用某个存储,但不会把存储从存储列表中删除,默认使用第一个存储,即stash@{0},如果要使用其他个,git stash apply stash@{$num} , 比如第二个:git stash apply stash@{1}
(6)git stash pop :命令恢复之前缓存的工作目录,将缓存堆栈中的对应stash删除,并将对应修改应用到当前的工作目录下,默认为第一个stash,即stash@{0},如果要应用并删除其他stash,命令:git stash pop stash@{$num} ,比如应用并删除第二个:git stash pop stash@{1}
(7)git stash drop stash@{$num} :丢弃stash@{$num}存储,从列表中删除这个存储
(8)git stash clear :删除所有缓存的stash
参考博客:
5.8 clone
下载某一个非常大的repository的时候,如果不是用来做开发,不需要把所有的历史版本信息都clone下来, –depth 1 可以指定只下载最近一次提交的记录,–branch指定只下载某一个指定的分支。如果不指定,一般情况git clone拿到的都是master分支。
1 | |
nerd-fonts这个repository,即便只下载master分支最近一次提交,都有1G多。
如果需要clone多个分支,可以先在本地创建一个分支,然后再pull下来。
6 版本回退
情况一:未使用 git add 缓存代码时
实际上是从暂存区复制了一份代码来取代当前已经修改的代码
1 | |
情况二:已经使用了 git add 缓存了代码
1 | |
此命令仅撤销 git add 命令的操作。使用本命令后,本地的修改并不会消失,而是回到了情况一的状态。若要放弃本地的修改,需再执行情况一的操作。
情况三:已经用 git commit 提交了代码
1 | |
1 | |
报错解决:git reset –hard HEAD^ 后显示 more?的解决方案
情况四:想撤销之前的某一版本,但是又想保留该目标版本后面的版本
比如,我们commit了三个版本(版本一、版本二、 版本三),突然发现版本二不行(如:有bug),想要撤销版本二,但又不想影响撤销版本三的提交,就可以用 git revert 命令来反做版本二,生成新的版本四,这个版本四里会保留版本三的东西,但撤销了版本二的东西。
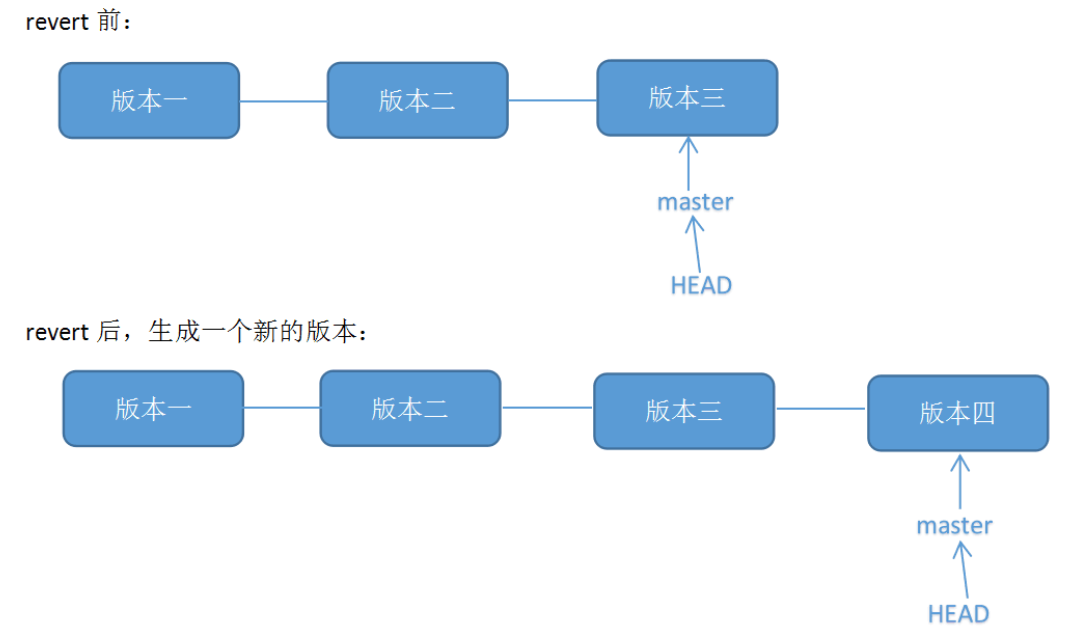
1 | |
情况五:修改 commit 的注释
1 | |
- git commit –amend,会出现上一次提交时的comment(即vim模式下查看记录)
- 按Insert键进入编辑模式,改好后Esc,:wq!保存退出
- git log 查看上一次 commit 的 comment 已经改好。
7 分支合并操作
merge
Git的合并有许多策略,默认情况下Git会帮助我们挑选合适的策略,当然如果我们需要手动指定,可以使用:git merge -s [策略名称],了解Git合并策略的原理可以使你对合并结果有一个准确的预期。
Fast-forward
Fast-forward是最简单的一种合并策略,如果dev分支是master分支的祖先节点,那么合并git merge dev的话,只会将dev指向master当前位置,Fast-forward是Git合并两个没有分叉的分支时的默认行为。
Recursive
Recursive是Git在合并两个有分叉的分支时的默认行为,简单的说,是递归的进行三路合并。
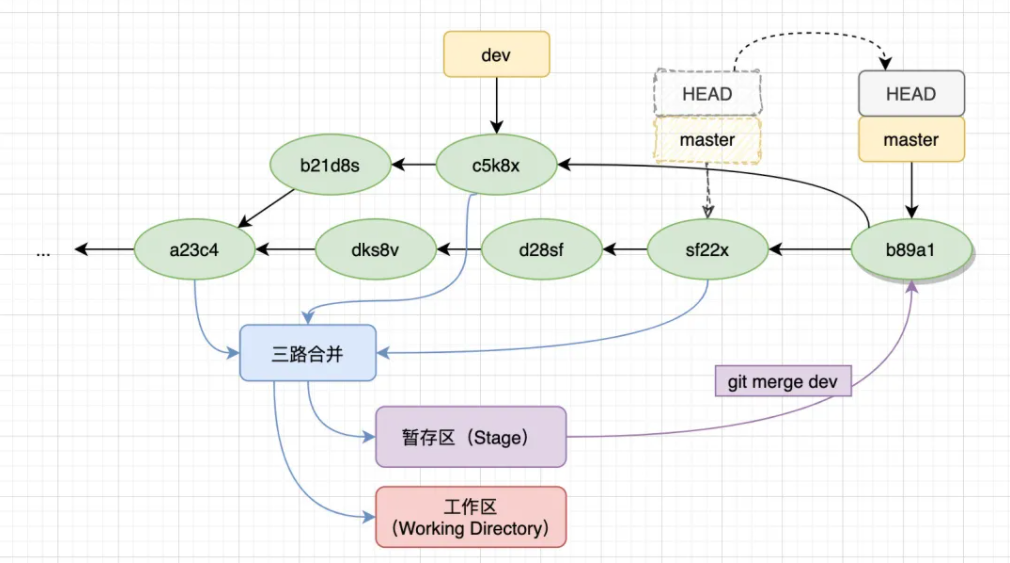
这里出现了一个新名词——三路合并(three-way merge),也是我们接下来讲解的重点。我们先搞清楚合并的整体链路。
- 首先dev分支的c5k8x与HEAD指向的sf22x,再加上它们的最近公共祖先a23c4先进行一次三路合并;
- 然后将合并后的结果拷贝到暂存区和工作区;
- 再然后产生一次新的提交,该提交的祖先为dev和原master;
分支合并的原理
首先,我们来看看两个文件如何合并:
下图所示为test.py中某一行的代码,如果我们要将A/B两个版本合并,就需要确定是A修改了B,还是B修改了A,亦或者两者都修改了,显然这种情况下分辨不出来。
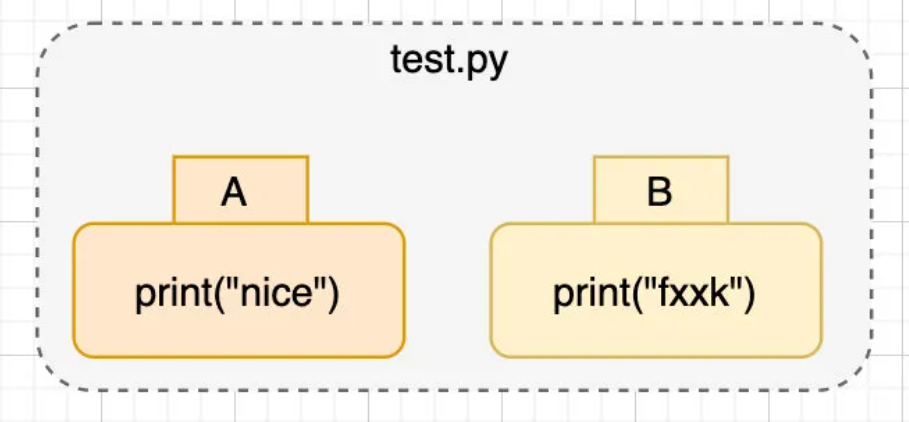
因此,为了实现两个文件的合并,我们引入三路合并:
如下图所示,很显然A与Base版本相同,B版本的修改比A版本新,因此将A/B合并后,得到的就是B版本。
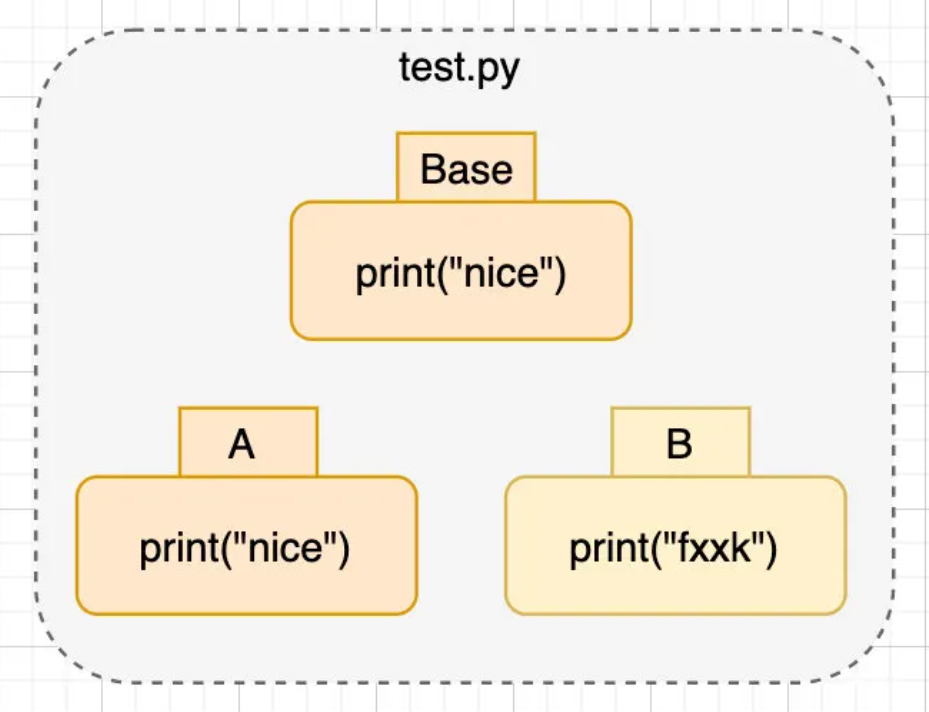
聪明的读者看完上面的例子,就会想到,要是A/B和Base都不一样怎么办?这就是接下来要讲的问题了。
冲突
当出现下图这种情况时,一般就需要我们手动解决冲突了。
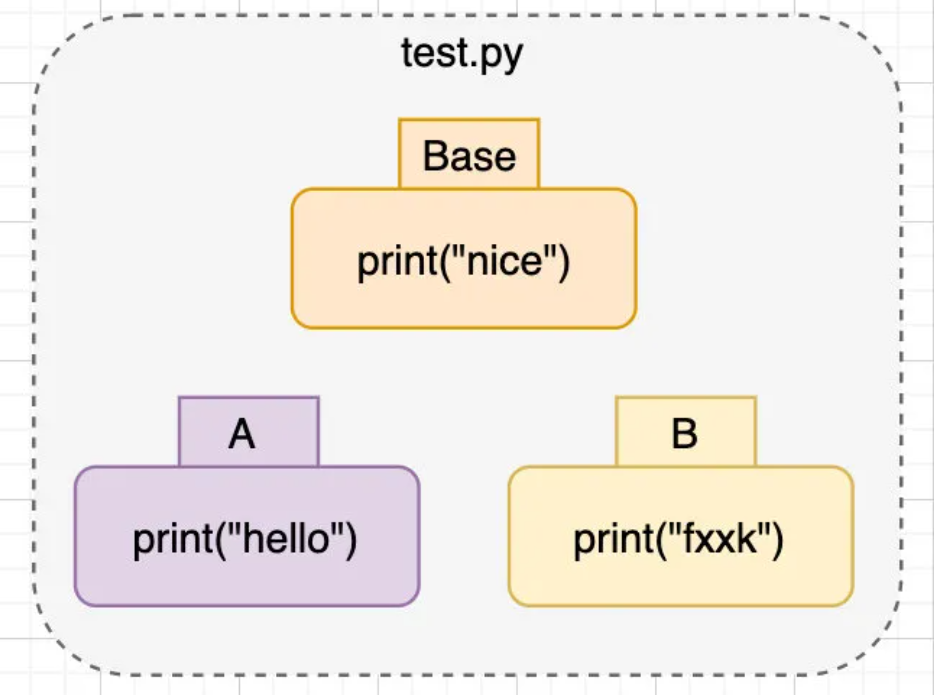
也就是我们在合并代码时往往会看到的一种情况:
1 | |
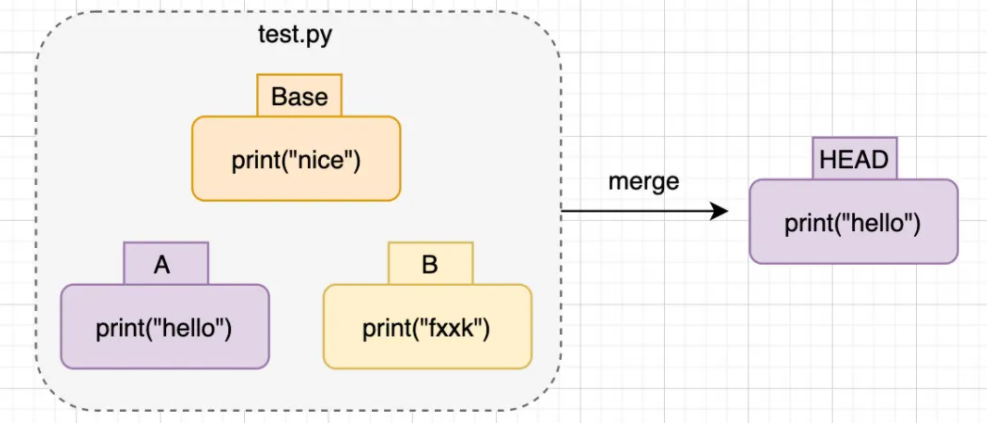
对于新手而言,看到这个箭头可能有点摸不着头脑,到底哪个是哪个呢?其实分辨起来很简单,中间的=======是分隔符,到最上方的<<<<<<之间的内容,是HEAD版本,也就是当前的master分支,而到最下方>>>>>>之间的内容,则是分支B的,我们只需要删除箭头,保留所需要的版本即可:
1 | |
最终合并结果:
递归三路合并
在实际的生产环境中,Git的分支往往非常繁杂,会导致合并A/B时,能找到多个A/B的共同祖先,而所谓的递归三路合并就是,对它们的共同祖先继续找共同祖先,直到找到唯一一个共同祖先为止,这样可以减少冲突的概率。
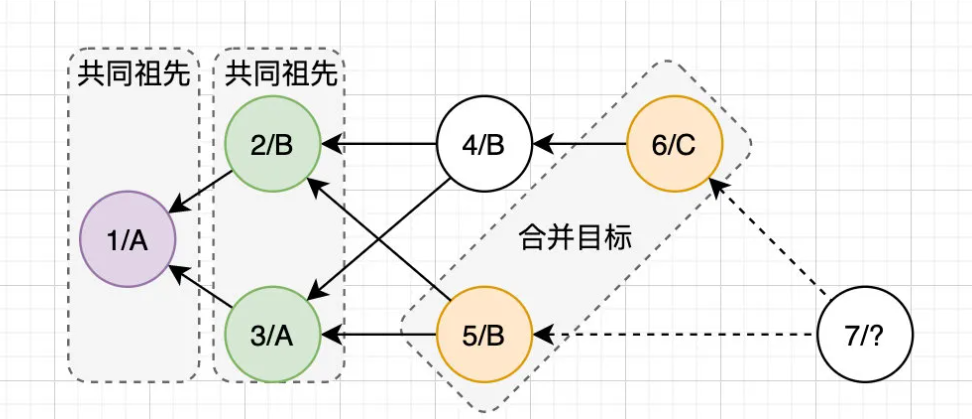
如上图所示,我们要合并5和6,就需要先找到5/6的共同祖先——2和3,然后再继续找共同祖先——1,当我们找到唯一祖先时,开始递归三路合并,先对1、2、3进行三路合并,得到临时节点2’/B:
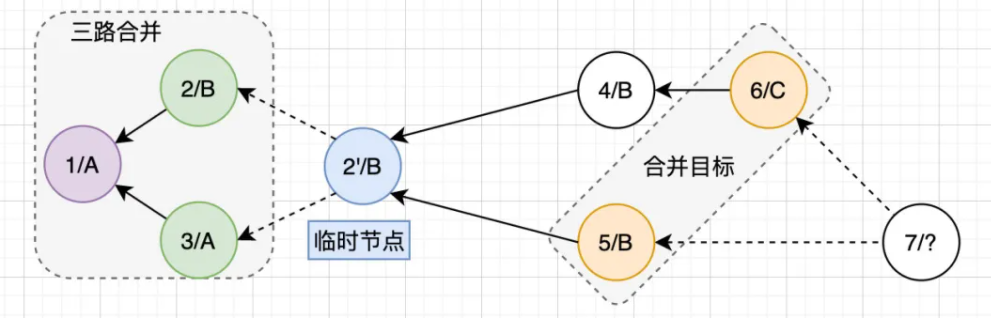
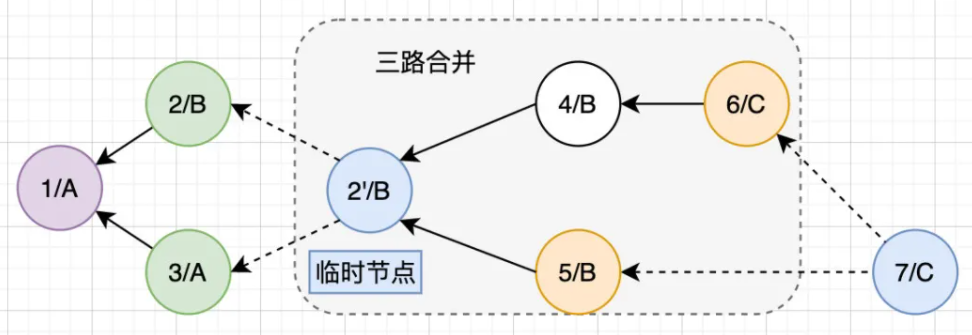
接下来继续对2、5、6进行三路合并,得到7/C:
rebase
当我们处于dev分支,然后使用git rebase master时,可以理解为把dev分支上的部分在master分支后面重新提交了一遍(重演),具体看下图:
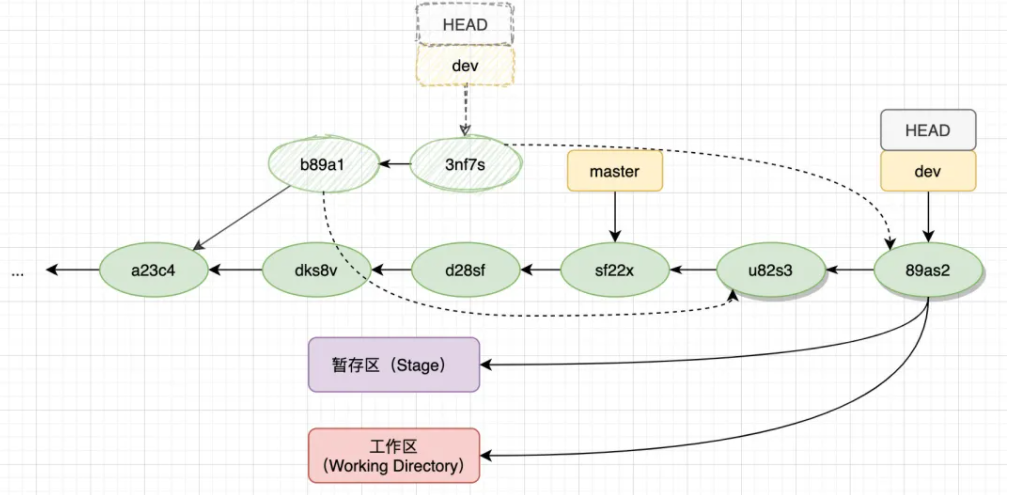
首先找到dev分支和master分支的祖先a23c4,然后从a23c4到dev所在路径上的节点,都通过回放的方式插入到master之后,注意,这里“复制”的过程中,commitId是会改变的。同时,dev旧分支上的节点因为没有了引用则会被丢弃。
⚠️该篇章内容源自某篇公众号推文,当时做笔记忘了附上文章出处,此处冒犯了,作者可联系我加上出处或删除内容~
8 Git提交规范
8.1 总体方案
目的
- 统一团队
Git commit日志标准,便于后续代码 review,版本发布以及日志自动化生成等等。 - 统一团队的 Git 工作流,包括分支使用、tag 规范、issue 等
Git commit 日志参考案例
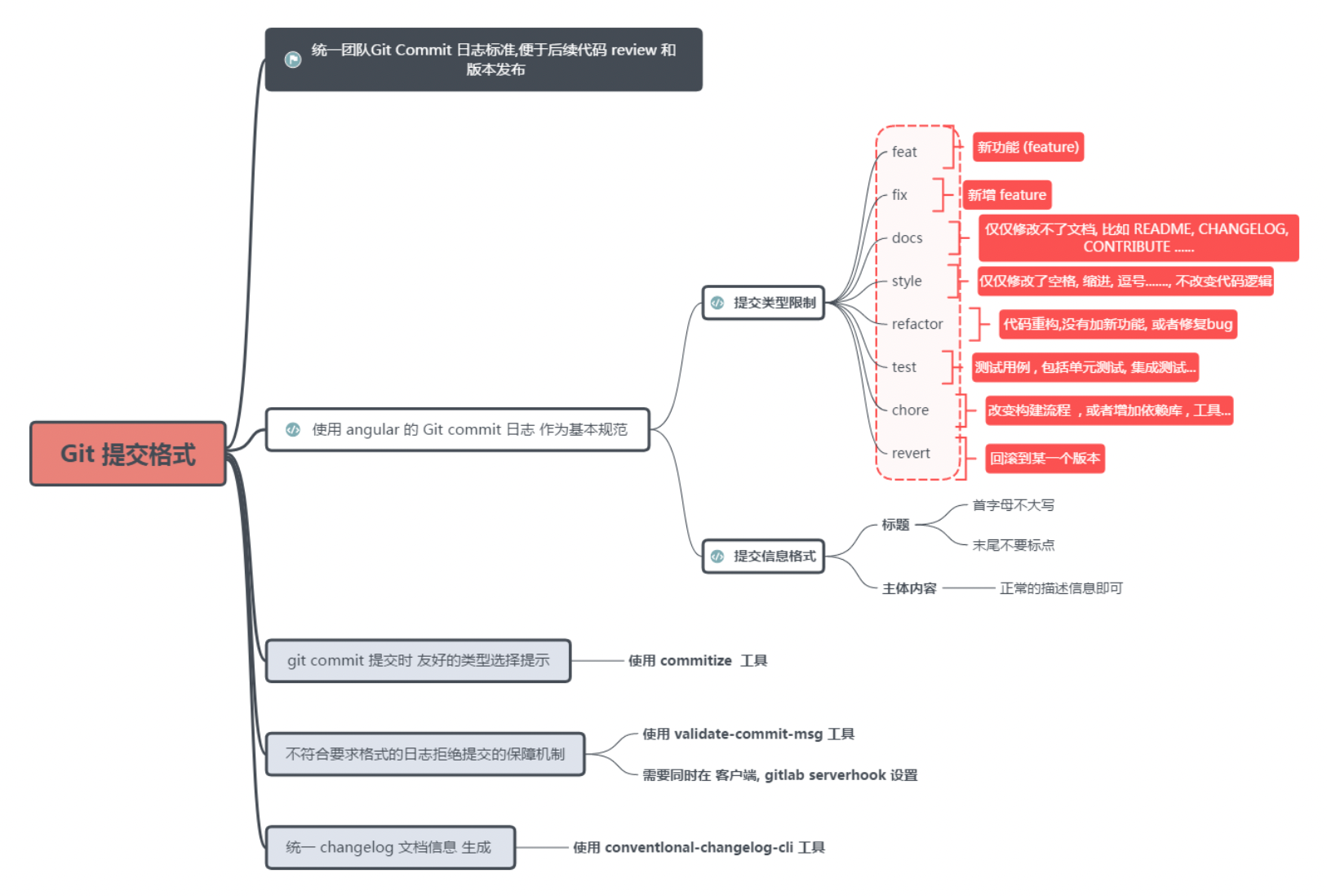
8.2 Git commit日志基本规范
1 | |
type
type代表某次提交的类型,比如是修复一个bug还是增加一个新的feature。
- feat: 新增 feature
- fix: 修复 bug
- docs: 仅仅修改了文档,比如 README, CHANGELOG, CONTRIBUTE等等
- style: 仅仅修改了空格、格式缩进、逗号等等,不改变代码逻辑
- refactor: 代码重构,没有加新功能或者修复 bug
- perf: 优化相关,比如提升性能、体验
- test: 测试用例,包括单元测试、集成测试等
- chore: 改变构建流程、或者增加依赖库、工具等
- revert: 回滚到上一个版本
scope
scope用于说明 commit 影响的范围,比如数据层、控制层、视图层等等,视项目不同而不同。
subject
subject是 commit 目的的简短描述,不超过50个字符。
- 以动词开头,使用第一人称现在时,比如
change,而不是changed或changes - 第一个字母小写
- 结尾不加句号(
.)
body
body 部分是对本次 commit 的详细描述,可以分成多行。下面是一个范例。
1 | |
有两个注意点。
- 使用第一人称现在时,比如使用
change而不是changed或changes。 - 应该说明代码变动的动机,以及与以前行为的对比。
footer
footer 部分只用于两种情况。
(1)不兼容变动
如果当前代码与上一个版本不兼容,则 Footer 部分以BREAKING CHANGE开头,后面是对变动的描述、以及变动理由和迁移方法。
1 | |
(2)关闭 Issue
如果当前 commit 针对某个issue,那么可以在 Footer 部分关闭这个 issue 。
1 | |
也可以一次关闭多个 issue 。
1 | |
格式要求:
1 | |
参考博客:
8.3 Git分支与版本发布规范
- 基本原则:master为保护分支,不直接在master上进行代码修改和提交。
- 开发日常需求或者项目时,从master分支上checkout一个feature分支进行开发或者bugfix分支进行bug修复,功能测试完毕并且项目发布上线后,将feature分支合并到主干master,并且打Tag发布,最后删除开发分支。分支命名规范:
- 分支版本命名规则:分支类型 _ 分支发布时间 _ 分支功能。比如:feat_20170401_fairy_flower
- 分支类型包括:feat、 fix、refactor三种类型,即新功能开发、bug修复和代码重构
- 时间使用年月日进行命名,不足2位补0
- 分支功能命名使用snake case命名法,即下划线命名。
- Tag包括3位版本,前缀使用v。比如v1.2.31。Tag命名规范:
- 新功能开发使用第2位版本号,bug修复使用第3位版本号
- 核心基础库或者Node中间价可以在大版本发布请使用灰度版本号,在版本后面加上后缀,用中划线分隔。alpha或者belta后面加上次数,即第几次alpha:
- v2.0.0-alpha.1
- v2.0.0-belta.1
- 版本正式发布前需要生成changelog文档,然后再发布上线。
8.4 commit模板
事先说明,这里只是记录一下有这么一种配置方式,但是相比于下面的其他方式,该方式显得不太让人满意,推荐使用后面的其他配置方式。
为了更好地遵循Git Comment发布规范,可以在git的全局变量中配置一个commit模板,每次执行 git commit 指令(不携带其他参数)的时候,就会通过指定的编辑器打开这个模板,方便提交comment。通过以下方式配置的环境会记录在 ~/.gitconfig 中,也可以直接修改该文件改变配置。
1 | |
.git_commit_template模板文件
1 | |
8.5 validate-commit-msg
validate-commit-msg是一个托管在npm平台的工具包,用来约束git commit的comment规范。似乎只是校验comment是否符合规范,但是并不会引导你去编写符合规范的comment。折腾了一段时间,感觉不是很符合我的预期,这里仅作记录。整理完最佳实践后又回过头来看了下这个接入方法,其实用的工具都是差不多的,只是README写的不详细,后端人员一下子理解不了。
接入方法参考commit-message-test-project项目。具体步骤如下:
- 第一步:在工程跟目录下的package.json文件加入如下代码所示的scripts和dependencies内容,版本号为3位版本号(通过npm安装)。
1 | |
- 第二步:在工程根目录新建.vcmrc文件,并且文件内容为
1 | |
接入后的操作流程
- 第一步:创建一个feature分支或者bugfix分支
1 | |
- 第二步:将代码提交到本地Git仓库,并填写符合要求的Commit message格式
1 | |
- 第三步:将代码同步到远程Git仓库
1 | |
- 第四步:自动生成changelog,并打Tag发布
1 | |
8.6 Git Commit Template
上面的操作和配置还有有点复杂,而且不是那么智能,在idea中可以安装Git Commit Template插件,通过该插件可以根据提示填写commit信息,由插件负责组织commit comment的格式。
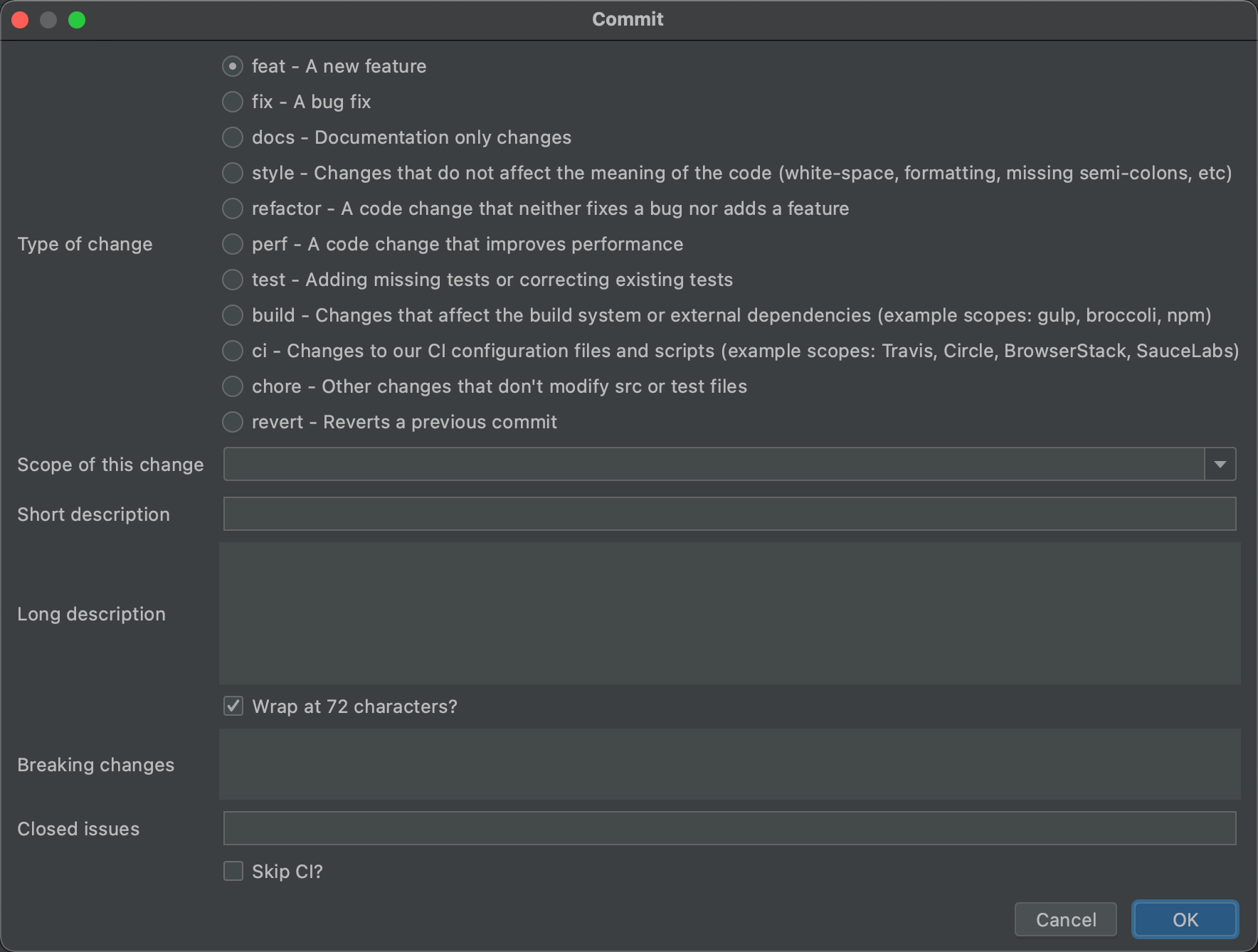
这种方式的话,直接填空就行了,不过只能在idea中使用(或者别的IDE),稍有不足。
8.7 最佳实践
🙏感谢 @前端左小白 整理该内容,并且在我寻求最佳实践的同一天发布了bilibili教学视频,对我帮助很大。
整个最佳实践分为3个部分,分别是:
- commitizen引导式comment填写
- husky+commitlint强制性规范校验
- standard-version生成changelog。
由于我并不是前端工程师,强迫症导致不喜欢在工程目录留存一些多余的文件/目录,所以后面设计的各项插件,我都尽可能做全局安装+配置,只有部分配置文件保留在工程目录下。
commitizen引导式comment填写
commitizen 是一个 cli 工具,用于规范化 git commit 信息。
1 | |
安装完成后,以后使用 git cz 指令代替 git commit 做提交,即可开启引导式的comment填写!
特殊的fix类型提交
当选择的 type 是 fix 的时候,引导指令会询问是否有issues受本次提交的影响,如果有的话,可以填写fix相关issues的编号,这样就能够自动在github上回复或关闭该issue。
此外,在 short description 中如果带上了issue编号的话,会自动被加上超链接,这个挺不错的,建议直接在 short description 的最后用一个小括号带上issue编号就好,例如 this is a short description (#123)。
1 | |
husky+commitlint强制性规范校验
和上面提到的Git Commit Template插件类似,commitizen终归是防君子不防小人,如果有人直接使用 commit -m'some comments' 命令提交commit,仍然能够提交不符合规范的commit comment。因此通过commitlint来强制性的约束comment必须符合conventional commits规范(其实和validate-commit-msg做的事情是一样的,但这个配置少一点)。
这里面commitlint只起到规范校验的作用,而git commit后执行commitlint规范校验的行为是通过husky钩子来实现的,husky保证commitlint规范校验在git commit指令键入之后被执行。
1 | |
有一个小问题,使用commitlint之后,如果再通过IDEA的commit窗口提交代码,会报错。。说找不到commitlint。
1 | |
检查了一下,和commitlint是否使用全局配置没有关系,暂时没有比较好的解决方式,有两种妥协的处理方法:
- 以后都不使用IDEA的commit窗口提交代码,全在命令行提交;
- IDEA的工程就不做husky钩子配置了,也就是说,什么配置都不用做,但是必须使用以下两种方式提交代码:
- 用Git Commit Template插件来生成comment然后再通过commit窗口提交;
- 使用commitizen从命令行提交。
当然还是推荐第二种方法啦,连配置都不用做了,自己约束好自己问题不大。
standard-version生成changelog
standard-version是一个用来控制版本发布的工具。
1 | |
使用说明:
1 | |
标签和版本号不会在 git push 的时候自动推送到github,需要单独手动推送。
1 | |
注意,不是每一次commit都应该生成一次tag,而是应该在有一个较为完整的改动/新增完成之后(可能涉及到众多的commit),才统一发布一个tag/release。在每次 git cz 之后,根据type以及一些其他因素的不同,npx standard-version 会自动调整版本发布的编号,比如一次fix一般版本号+0.0.1,默认一般+0.1.0,如果有重大feature则+1.0.0,大致是这么个规律,后面需要可以再深入研究一下。
执行npx standard-version 之后会追加信息到changelog文档,并且自动单独做一次commit提交。
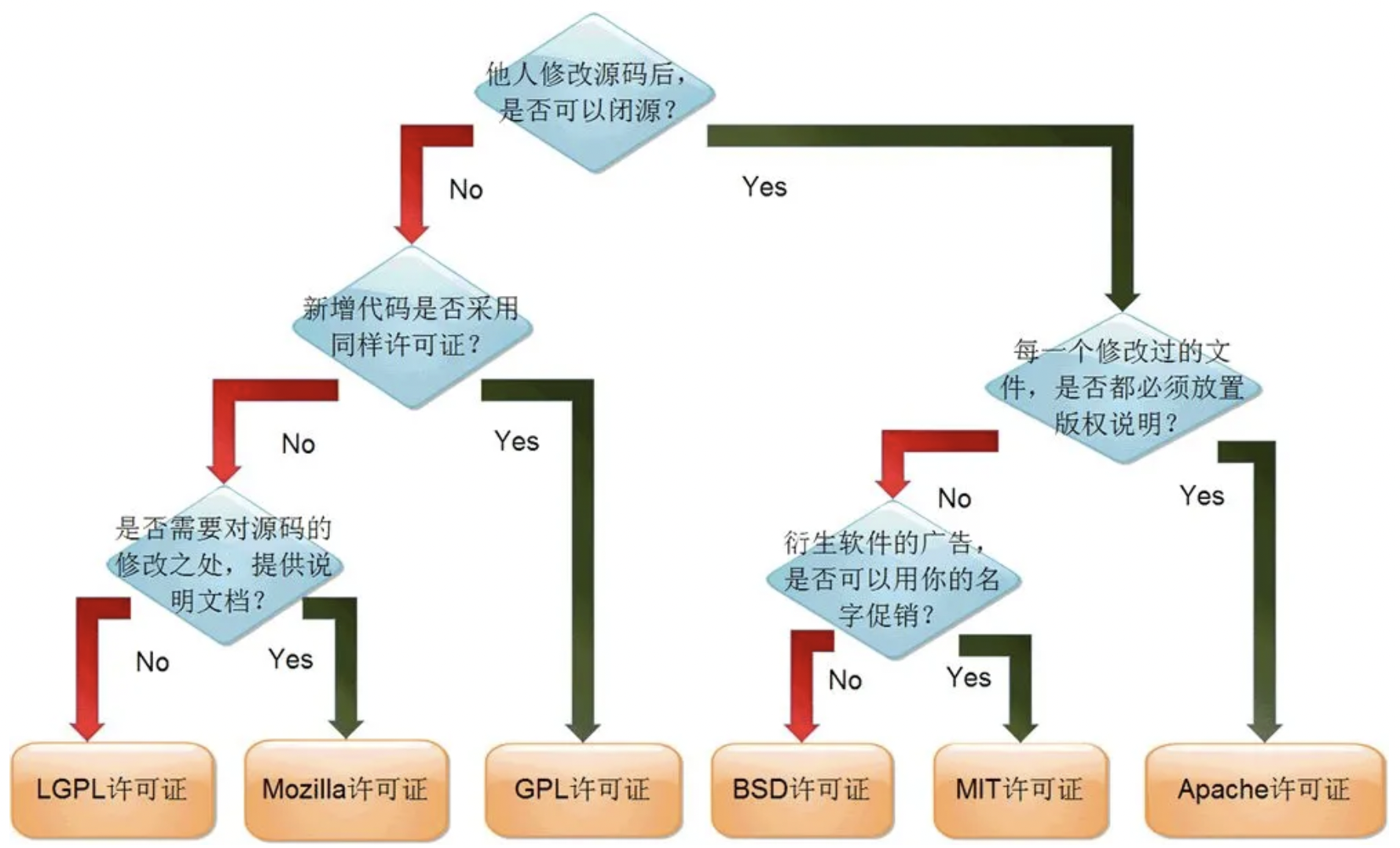
9 常用License
GPL
GPL 是 GNU General Public License(GNU 通用公共许可证)的缩写形式。
- 任何一套软件,只要其中使用了受 GPL 协议保护的第三方软件的源程序,并向非开发人员发布时,软件本身也就自动成为受 GPL 保护并且约束的实体。也就是说,此时它必须开放源代码。
- 允许去掉所有原作的版权信息,只要你保持开源,并且随源代码、二进制版附上 GPL 的许可证就行,让后人可以很明确地得知此软件的授权信息。GPL 精髓就是,使软件在完整开源的情况下,尽可能让使用者得到自由发挥的空间,使软件得到更快更好的发展。
- 无论软件以何种形式发布,都必须同时附上源代码。
- 开发或维护遵循 GPL 协议开发的软件的公司或个人,可以对使用者收取一定的服务费用。但必须无偿提供软件的完整源代码,不得将源代码与服务做捆绑或任何变相捆绑销售。
LGPL
LGPL 是 GNU Lesser General Public License (GNU 宽通用公共许可证)的缩写形式。
GPL和LGPL对比
- 基于 GPL 的软件允许商业化销售,但不允许封闭源代码。如果您对遵循GPL的软件进行任何改动和/或再次开发并予以发布,则您的产品必须继承 GPL 协议,不允许封闭源代码。
- 基于 LGPL 的软件也允许商业化销售,但不允许封闭源代码。如果您对遵循 LGPL 的软件进行任何改动和/或再次开发并予以发布,则您的产品必须继承LGPL协议,不允许封闭源代码。但是如果您的程序对遵循 LGPL 的软件进行任何连接、调用而不是包含,则允许封闭源代码。
BSD
BSD开源协议是一个给于使用者很大自由的协议。基本上使用者可以自由的使用,修改源代码,也可以将修改后的代码作为==开源或者专有软件==再发布。
当使用了BSD协议的代码,或者以BSD协议代码为基础做二次开发自己的产品时,需要满足三个条件:
- 如果再发布的产品中包含源代码,则在源代码中必须带有==原来代码==中的BSD协议;
- 如果再发布的只是二进制类库/软件,则需要在类库/软件的文档和版权声明中包含原来代码中的BSD协议;
- 不可以用开源代码的作者/机构名字和原来产品的名字做市场推广。
因此,很多公司企业在选择开源软件的时候都首选BSD协议,因为可以完全控制这些第三方的代码,而且在必要的时候可以进行修改或者二次开发。
MIT
MIT是和BSD一样宽范的许可协议,作者只想保留版权,而无任何其他了限制。也就是说,你必须在你的发行版里包含原许可协议的声明,无论你是以二进制发布的还是以源代码发布的。
Apache License
Apache Licence是著名的非盈利开源组织Apache采用的协议。该协议和BSD类似,同样鼓励代码共享和尊重原作者的著作权,同样允许代码修改,再发布(作为开源或商业软件)。需要满足的条件也和BSD类似:
需要给代码的用户一份Apache Licence;如果你修改了代码,需要在被修改的文件中说明;在延伸的代码中(修改和有源代码衍生的代码中)需要带有原来代码中的协议,商标,专利声明和其他原来作者规定需要包含的说明;如果再发布的产品中包含一个Notice文件,则在Notice文件中需要带有Apache Licence。你可以在Notice中增加自己的许可,但不可以表现为对Apache Licence构成更改。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!